
Understanding our searches and listings.
End of last year, we started working on ways to understand our visitors and one of the things we were interested in, was to understand what they searched and how often they found what they were looking for. On the other side of things, we also wanted to know what happens to the listings our sellers posted, things like how often they show up and in what search queries. Then there were things like, what are the most popular car makes and models, in which regions, and other patterns that we may find. In the end we wanted to correlate all this to understand what is happing on our sites, from the individual listings to the bigger picture. Eventually this will help us to improve our systems, and later integrating this data within the sites may provide an improved experience for both buyers and sellers.
We started exploring ways we could store this data. Getting the data was the easy part as what the user searches comes to our internal API. The challenge was storing the data and in a manner that later on not only be used to understand but integrate back into our system.
There were two important questions we asked ourselves. One was where to store the data and the second one was how to make it meaningful?
So how do we store this data?
As we already were using Apache Solr as the search engine for our sites, our first thought was to somehow enable logs in Solr and get those logs into a format, which we could analyze.
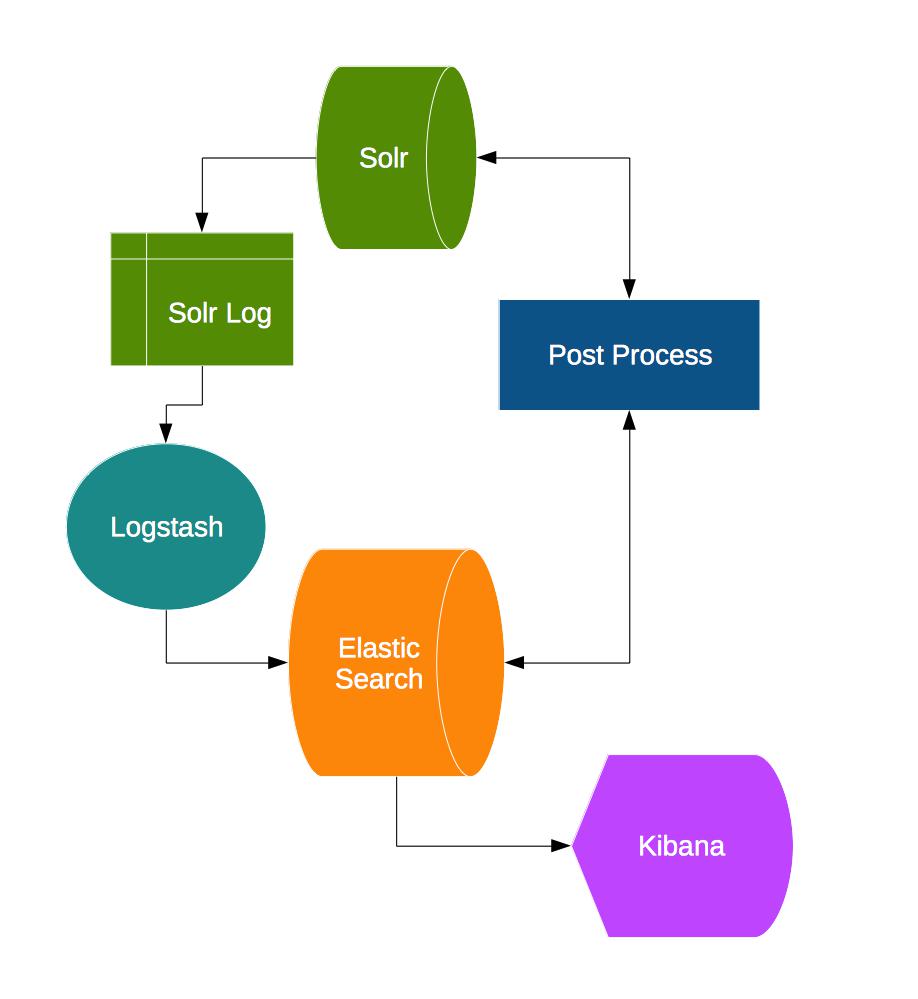
On our search for something that did this, we came upon the ELK (Elasticsearch, Logstash, Kibana) stack, which almost sounded like what we wanted.
The Logstash would take the Solr logs and dump them into Elasticsearch, the Elasticsearch would allow us to query it, and Kibana would use the Elasticsearch to graph it. Elasticsearch is a search server based on Lucene which provides distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is written in Java and is open source using the Apache License.
We did a run the ELK using Solr logs. It did work but then came the inflexibility. Logs contained only what the user searched but what it didn’t have is where the query generated and other data we may need. Also the other problem was, how to get what the visitor saw as a result of the search. That would require post processing as we would have to pick the search query and fill it with result at a later time.
We put aside ELK for now and started looking for alternatives. We went doing so, ruling out RDBMS, by starting to explore some of the nosql databases and other post processing technologies. We went through MongoDB, Hadoop, HIVE, Cassandra and VoltDB.
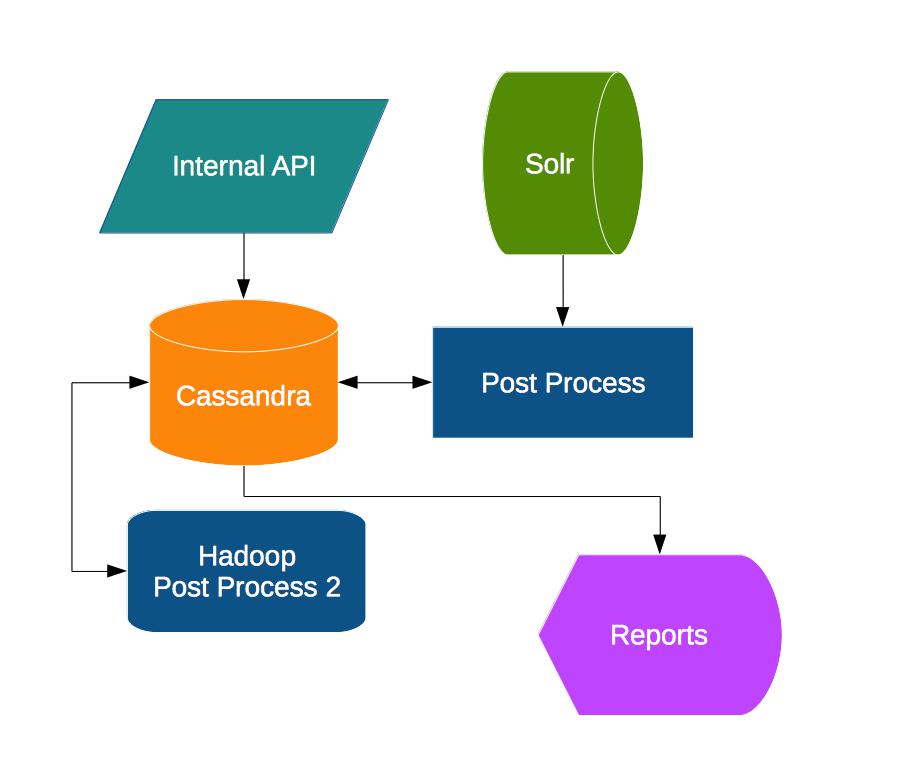
One of the solutions that we worked out was involving Cassandra. As Cassandra benchmarks were the best, with the high number of writes in less time and it’s compressing of data on storage therefore requiring less disk space, it seemed almost the thing we needed.
We first created a basic schema, creating collections, for Cassandra and wrote an API endpoint to write some dummy data into it. Then we ran basic load tests using JMeter and storing the data. The writes were great, and the data space taken by Cassandra was low. But while implementing this, we felt we were reworking the schema and rethinking about what we want to store, changing then implementation. One of the thing that was a bit bothering is the post processing we might have to do if we chose Cassandra. As the data would be raw format, we would have to create usable data, working and changing the schema initially to get to the point where we have the desired result. Plus then do post processing on it. Since we are only beginning to explore how the data we wanted, could be used, we needed something that would not require less processing and would bring our data into a format which we can query for aggregations and perform analytical queries on.
Elasticsearch.
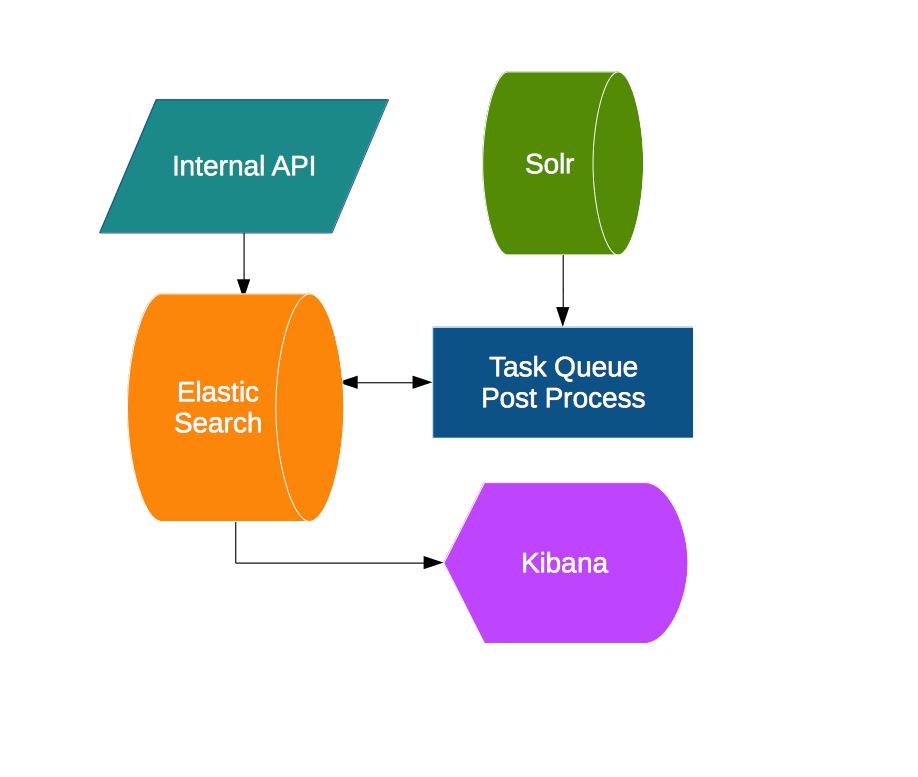 We then went back to ELK stack, and decided, we didn’t need Logstash. So just started doing a similar process above for testing, but just using standalone Elasticsearch for now. From our experience with Cassandra, we know the first thing to do was to finalize the fields from the search query we wanted to save, and what data from the search result we wanted to record for each individual search query. All this is anonymous data but having this decided early on was a plus.
We then went back to ELK stack, and decided, we didn’t need Logstash. So just started doing a similar process above for testing, but just using standalone Elasticsearch for now. From our experience with Cassandra, we know the first thing to do was to finalize the fields from the search query we wanted to save, and what data from the search result we wanted to record for each individual search query. All this is anonymous data but having this decided early on was a plus.
We did a rough calculation using the numbers from our New Relic and Google Analytics and came up with a rough number of requests we were anticipating. We then wrote scripts to populate dummy data into Elasticsearch and see the size it takes to store documents (with each document containing average number search parameters and one search result). We had an estimated size of data that we would get but what about the load? So we started by sending concurrent write requests to the server. We started off with JMeter to create the concurrent requests. With limited success, we were able to test it. Unlike Cassandra, which was on our local server, Elasticsearch we had deployed on an AWS machine. So we ran into a bandwidth bottleneck while running testing. So we decided to run the benchmark form another AWS machine, we had on the network with the Elasticsearch machine. During this time, we moved out of JMeter and started using Apache Benchmark for the concurrent tests. And this is when we decided to go with Elasticsearch. Elasticsearch was easily managing the number of writes we estimated and the data we saw was easy to query. The only concern we saw was the disk size. Our initial assessment showed, 2 TB of data for 3 months (if we had one search query with one search result), which would be a lot more as the search results are normal 10 at average.
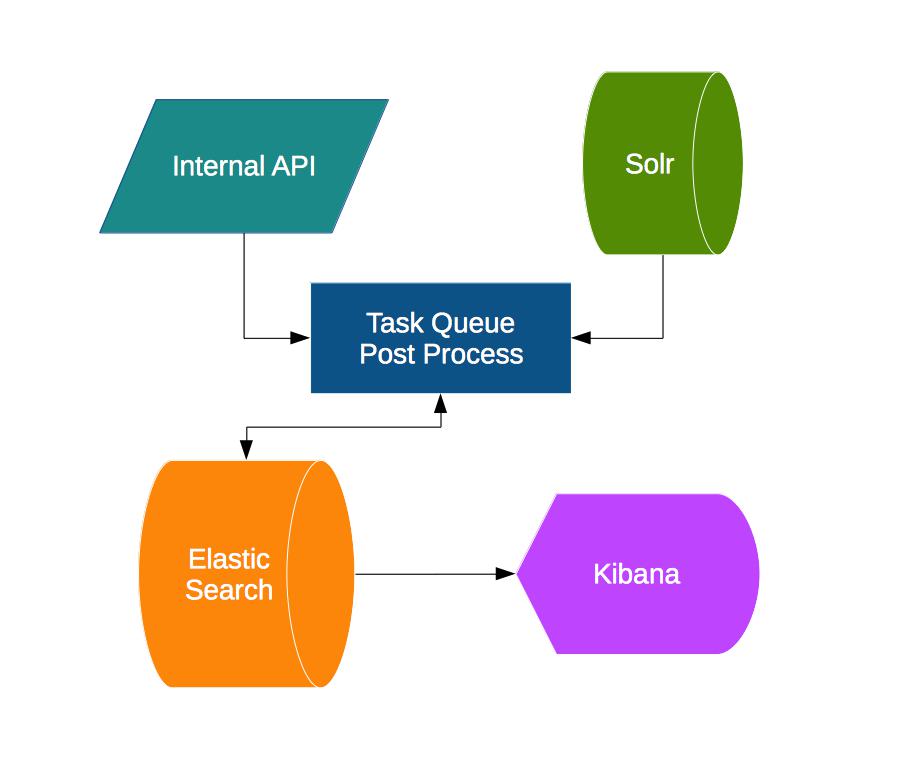
Then we came to the question of how to get the data in the Elasticsearch. Of course the API directly writing to Elasticsearch was the easiest solution. But there were three concerns in this.
First was we didn’t want our API endpoints doing extra work and slowing down. Secondly, in case of some delay in Elasticsearch write, we didn’t want our API endpoint to slow down. Thirdly, in case of error in Elasticsearch, we didn’t want it affecting the original endpoint and also have a certain retry mechanism.
To avoid all this, we decided to let our Queue server (Fresque) do the writing to Elasticsearch. Our API would just create a job with the search query and forget about it, without having to do anything else. It was the job’s task to generate the Solr results, process the search query parameters, and do any post processing work and then save it into Elasticsearch. This would ensure our normal site would function as is, but the load would shift to the queue server. I’ll discuss Fresque in detail and other load testing related things in the Part 2 of the article.
Why Elasticsearch and not Solr?
There is the question that was nagging, in our minds, why didn’t we just go ahead and use Solr. Its also based on Apache Lucene, and has great search feature, and we already have experience managing it. Well the answer lies in what we needed in this case. We chose Elasticsearch cause of how it indexes data, the analyzers we can use and also the ability to use the nested and parent-child data in it, but we mainly chose it because of the analytical queries it can do.
Solr is still much more for text search while Elasticsearch tilts more towards filtering and grouping, the analytical query workload, and not just text search. Elasticsearch has made efforts to make such queries more efficient (lower memory footprint and CPU usage) in both Lucene and Elasticsearch. Elasticsearch is a better choice for us as we don’t need just text search, but also complex search-time aggregations.
The way ElasticSearch manages shards / replication is also better than Solr, as it’s a native feature within it and more control but we didn’t put that in the consideration, although that itself is a good reason.
Conclusion
So in the end, we went with Elasticsearch, compromising on the high data size, for it’s ability to aggregate data and make the data searchable and also enable us to perform analytical queries, reducing the effort to process data. Elasticsearch can transform data into searchable tokens with the tokenizer of our choice and perform any transformation on it and then index the needed fields. It also supports both nested objects and parent-child objects, which is a great way to make sense of complex data. Then there is the wonderful Kibana. It can plot graphs using ElasticSearch and give us instant meaning.
Next up
Elasticsearch – Part 2 – Implementation and what we learned.
Elasticsearch – Part 3 – A few weeks fast forwarded and the way ahead.